Finetuning on Real Images in My Album

Disclaimer
For ethical and legal reasons, I did not and will not share the source images, trained models, or the model outputs publicly or with anyone. The images used for training were self-taken or collected from publicly available sources for the purpose of research. As an exception, output images of certain identities were uploaded in the final project report (not this blog), with the consent of the individuals involved.
Introduction
As the course project of the image generation course, we are tasked with finetuning an image generation model. I picked up an idea that I has been thinking about for years: training on real images in my album such that the model learns the appearance of my close friends. The following is my journey.
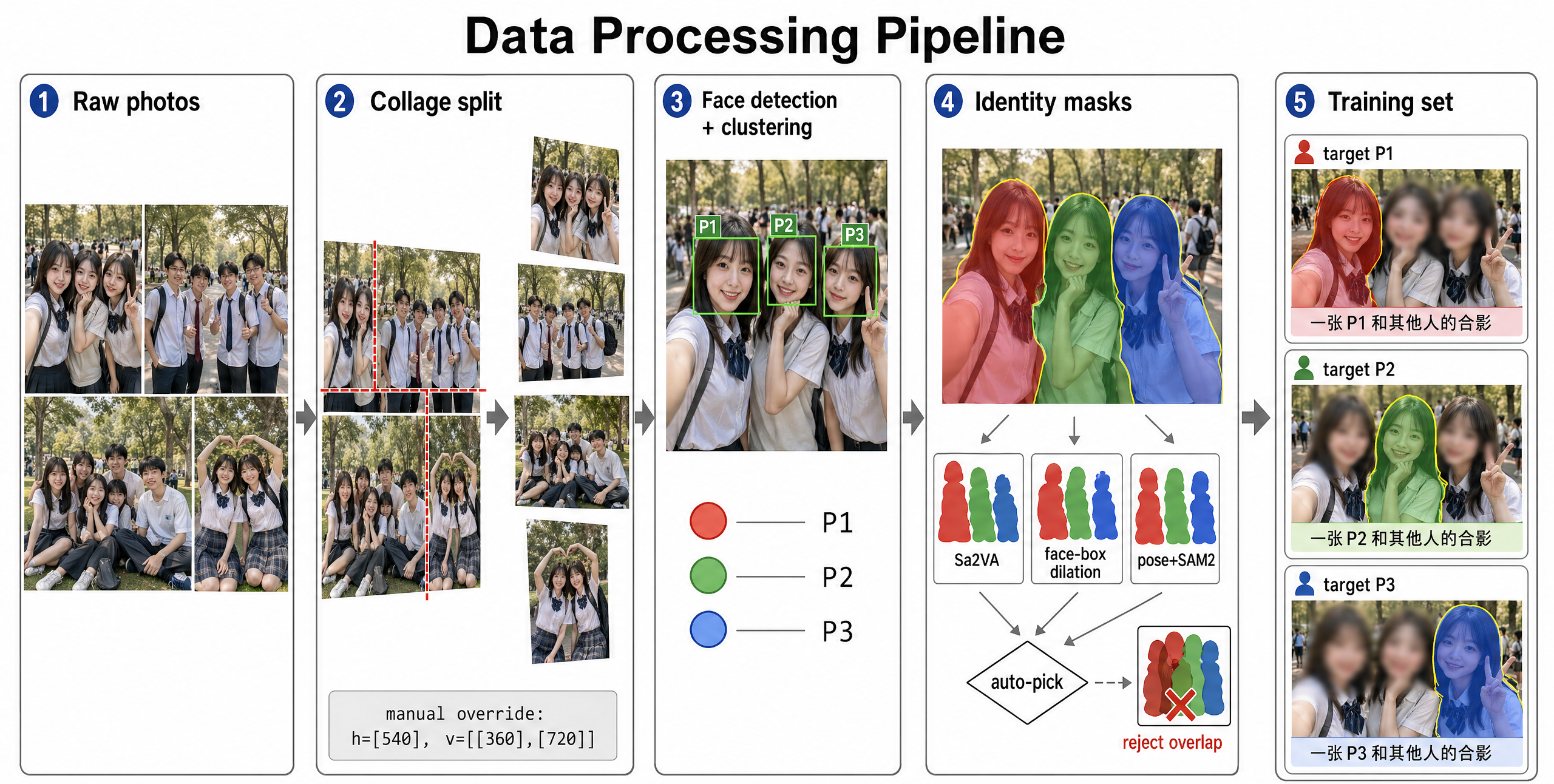
(Above is an illustration of the entire pipeline. The example images are AI generated and not from the dataset.)
Data Collection
I’ve been a fan of image generation since around 2021 or 2022. By the time diffusion models haven’t fully taken off. I remembered playing with stylegan3 and early diffusion models on colab. I watched the release of computervis/latent diffusion, stable diffusion, dalle2, imagen … and the rise of the image generation community.
Then at an event upon my high school graduation, everyone in the entire grade took photos with each other, including me. I knew this was a opportunity to collect a large number of photos of similar distribution, so I inquired my friends for photos to be trained on in future. I also collected photos in that event from publicly available sources. This resulted in a dataset of around 400 raw photos.
BTW, I also collected hundreds of photos of nucleic acid test kits for the same purpose.
It didn’t come to me that this project was shelfed until 3 years later when my classmates that felt so close have scattered so far. The reason was not the huge model capability improvements over the years, but the rise of autonomous coding agents that greatly reduced the engineering efforts of the entire pipeline.
Downloading Reddit
I didn’t go straight to finetuning. I need to know how others have done it and they are mostly on r/StableDiffusion. General purpuse web searching tools that coding agents have shouldn’index reddit well due to login walls. So I downloaded reddit posts (luckily there was a reddit archive site) and built local search tools. Over the course of a few agent sessions, I was able to find useful recipes for identity finetuning. And I consulted reddit posts in the later stages of the project as well.
Splitting Collages
Many photos in the dataset are collages of multiple photos. They need to be split into individual photos. While most collages are regular m*n grids or long vertical photo stacks, there are some irregular collage layouts. What’s worse, collages are often directly concatenated without explicit borders.
This makes it hard to split collages with traditional image processing techniques. At the beginning, I let the coding agent draft the initial version of rules, split the photos and present the results in an HTML page. I then manually identified common failure cases and let the agent refine the rules. This turned out inefficient after a few iterations even with complex heuristics. Instead, I had to manually label a set of missplit collages with similar layouts in the HTML page, and let the agent to use edge detection tools and direct visual and textual hints to determine exact split positions of each image. Finally, we got 1,000+ photos after splitting.
Side discovery: Long vertical photo stacks are nearly as clear as single photos after compression of online platforms.
Detecting Faces
The next step is to annotate who is in each photo. First, I needed to detect faces in the photos using bounding boxes. The process was similar: I let the agent search arxiv for SOTA models, set up the environment, run the code, and present the results. To increase recall, the agent used several techniques to upscale the photos to find small faces. But after reviewing I told the agent it’s the large missing faces that actually matter. Downscaling is actually needed to find faces larger then CNN receptive fields.
Then, clustering was used to group faces of the same person together (I don’t have a ground truth roster). The facial embeddings were surprisingly accurate and we got near perfect clusters after 2 rounds of clustering. The model correctly weather the alterations of rotation, lighting, size, and glasses. The rare failure cases were extreme angles and near-back views (human can reconize through clothing and partners). A pair of twins were also clustered together at the 2nd round.
I then manually labeled 100+ classmates and teachers I knew.
Masking and Facial Blurring
An important problem of my dataset is that every photo contains multiple people. The frequency of each person is also long-tailed. Thus I decided that each sample image should let the model learn only one identity, and use a simple rule based (not VLM based) template: “A groupcap of
Before introducing the two tricks, I’d like to briefly explain the training process of flow matching diffusion models.
1 | # Flow Matching: linear interpolation between data and noise |
For each sample image-caption pair (x_0, caption), we sample a random noise image x_1, and add the noise to the image with a random ratio (t for time), resulting in a noisy image x_t. The model is trained to predict vector v_target from the noisy image to the pure noise, with the noisy image, caption text and the noise ratio as input.
Above is a simplified explanation
The most important clarification is that modern diffusion models learn on VAE embeddings of images, not raw pixels.
The range of temperature t is not the entire [0, 1], but a smaller range depending on whether we want to learn the style (little noise) or structure (large noise) of the image.
And like all ML training, we may have batch size larger than 1.
LoRA is often used when finetuning with small datasets.
The masking trick is therefore to mask out the loss of background and other people in the image. The facial blurring trick is to blur the faces of other people in the input image before adding noise, so that the model focuses more on the target identity.
Masking is not trivial. Off-the-shelf instance segmentation is confused by pressed-together torsos, and pose-only methods drop the clothing region. We therefore used a heuristic selector among 3 methods including a Sa2VA-based one (SAM2 with LLaVA). Identitying a hand coming from behind someone’s shoulder is still an unsolved problem for my tested methods.
Training and Results
I trained Qwen-Image on ~100 high resolution photos and 5 selected identities (the long tail distribution remains). The resulting model are decent at generating the target identities. According to the feedback from my friends some of the output images of their own faces are self-recognizable (for ethical and meantal health reasons I only present the already cherry-picked results to them). Notably, the final model (training 5 identities together) generally learns better than the models trained on each identity separately, suggesting generalization through joint training.
Still, the resulting model is not perfect. A group photo of A and B results in two near-identitical persons that look at a blend of both. Generations sometimes drift from the target identity or even appear broken. In some other training experiments the output quality degrades, which looks like the model forgetting its final annealing data and falling back to general web images in the majority of its pretraining data.
Reflections
When my initial models performed worse then expected, I looked into my dataset, deeper than ever.
The training photos are, by any technical standard, bad: edge-of-frame selfie warp, mid-blink/laugh, half-turned heads, Re-compression smearing skin tones into plastic. Upon closer look the images did not reflect what the identities looked like in my memory, unlike a carefully edited studio photo. But these photos feel good to me because they carry the memory of my high school years and my classmates.
Second, even with a hundred-plus images per identity, it’s impossible to recover the full visual identity of a person, let alone any other characteristics. One identity’s real hairstyle is a short half-up ponytail, too short to show from the front in any training shot, so the model converges on her hair down. In group photos where the entire body is visible, the most frequent pose is standing with hands behind one’s back, so the model fails to learn hands. This experience convinced me that the sci-fi idea of “uploading” a person’s identity online is impossible with current sources of data.
A model finetuned on someone you know will always feel slightly off in ways those who know them notice and those who don’t never see. That asymmetry — between what a close friend knows and what can be derived from every digital record combined — is, for me, the actual deliverable.
- Title: Finetuning on Real Images in My Album
- Author: Stargazer ZJ
- Created at : 2026-05-05 14:19:04
- Updated at : 2026-05-05 22:42:37
- Link: https://ji-z.net/2026/05/05/Finetuning-on-Real-Images-in-My-Album/
- License: This work is licensed under CC BY-NC-SA 4.0.